
The modern enterprise perimeter has not just dissolved; it has evaporated into a fog of microservices, ephemeral functions, and distributed storage buckets. For the last decade, the mandate for IT leaders was speed. “Move fast and break things” was the philosophy that drove digital transformation, pushing organizations to adopt serverless architectures and cloud-native developments at a breakneck pace. We succeeded in moving fast, but in the process, we broke our visibility.
Today, the most significant risk to your organization is likely not the sophisticated external attacker pounding on your firewall. It is the data you have forgotten you possess. It is the “shadow data”; orphaned backups, unmonitored log files, and temporary development databases that exist outside your primary security controls.
This creates a dangerous paradox. We have more security tools than ever before, yet we are increasingly flying blind regarding where our sensitive data actually lives.
As previously covered, the shift toward rapid deployment often bypasses traditional governance. To understand the magnitude of this issue, we must look at the financial reality.
According to the Verizon 2025 Data Breach Investigations Report1 (DBIR), the proliferation of ‘Shadow AI’ has become a critical vulnerability. The report found that 72% of employees using Generative AI tools on corporate networks did so using personal email accounts, effectively bypassing corporate security oversight. This aligns with the broader finding that the ‘Human Element’ — including errors and policy circumvention- contributes to 68% of all confirmed data breaches, according to its 2024 version2 of the report.
That extra time, the “dwell time,” is where the silent failure occurs. When you cannot see your data, you cannot protect it, and you certainly cannot investigate it when it goes missing. This article explores why your cloud strategy requires a forensic upgrade and how to build a resilient architecture that accounts for the unknown.
The Serverless Blind Spot
The adoption of Serverless computing and Functions as a Service (FaaS) has revolutionized how we build software. It allows developers to push code without managing the underlying infrastructure, leading to rapid iteration and reduced operational overhead. However, this abstraction layer introduces a significant blind spot.
In a traditional on-premise environment, you knew exactly which servers held your data. In a serverless environment, data flows through ephemeral containers that spin up for milliseconds and then vanish. If your security model relies on installing agents on servers, you are effectively defenseless in a FaaS architecture.
To learn more about the specific mechanics of this risk, we recommend reviewing Serverless Security: Functions as a Service (FaaS),3 which details how the granular nature of serverless functions expands the attack surface. The core issue is that while the cloud provider manages the security of the cloud (the physical hardware and network), the customer remains responsible for security in the cloud (the data and application logic).
When developers spin up a new function to process customer data, they often create temporary storage buckets or log streams to debug that function. Once the feature is live, the function remains, but so do those temporary data stores. They become “zombie assets” — unmonitored, unpatched, and full of sensitive information.
This is not a theoretical risk. A research Comprehensive Multi-Vocal Empirical Study of ML Cloud Service Misuses4 identifies that 69% of examined cloud-based software projects contained service misconfigurations (misuses) that left them vulnerable or inefficient.
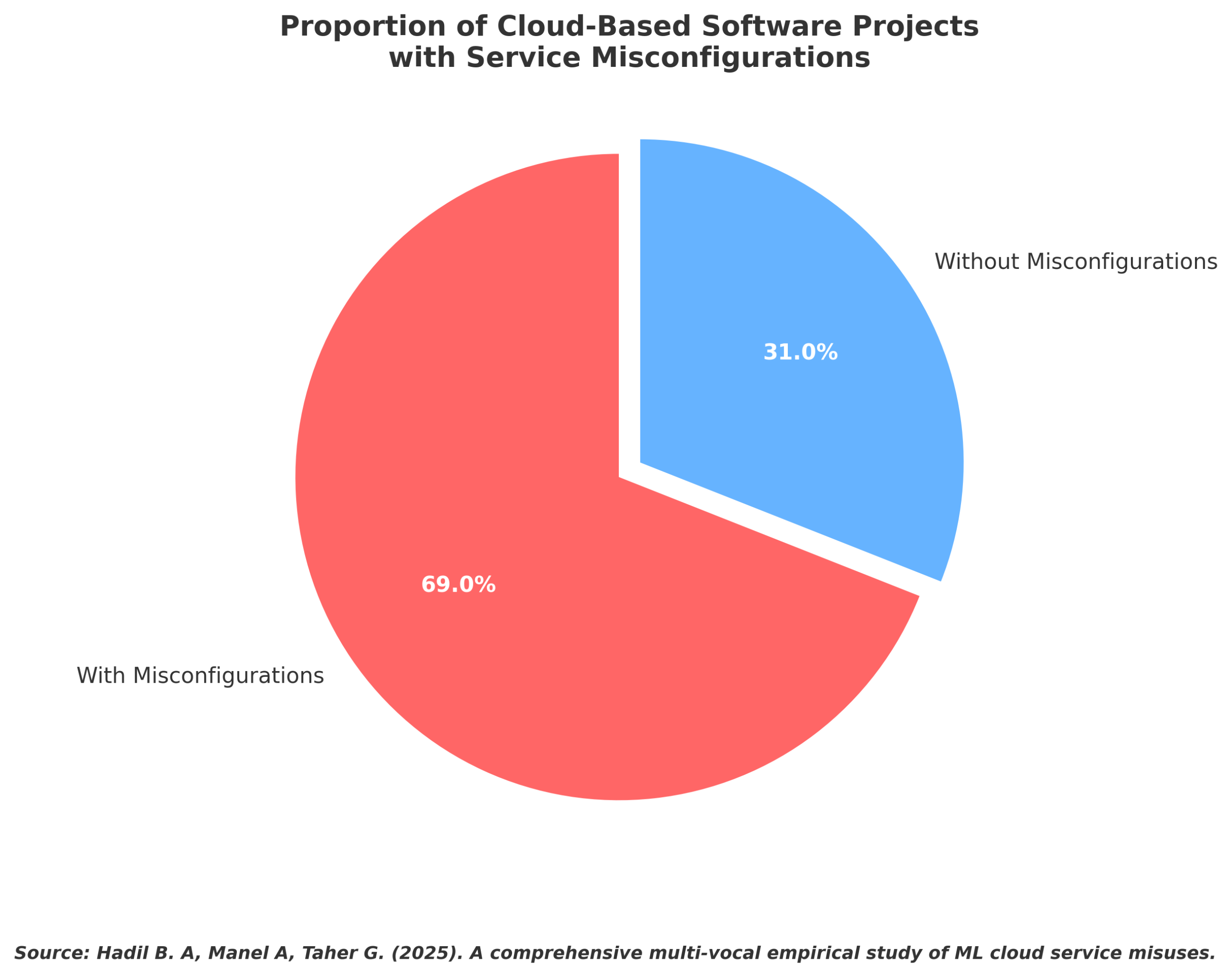
These assets are the low-hanging fruit for attackers. They do not need to exploit a zero-day vulnerability in your firewall; they simply need to find the storage bucket you forgot existed.
The High Cost of Silence
The proliferation of shadow data leads to “silent failures.” These are security incidents that do not trigger an immediate alarm because they happen in unmonitored environments. The attacker does not crash the system or encrypt the production database immediately. Instead, they dwell.
Dwell time is the duration between the initial compromise and the moment the organization detects it. During this window, attackers move laterally, map the network, and exfiltrate data slowly to avoid detection. Academic research published in the World Journal of Advanced Research and Reviews5(2025) reveals that healthcare breaches involving compromised user accounts often remain undetected for over 200 days. The study attributes this significant delay to the ‘stealth nature’ of credential-based attacks, which allow adversaries to mimic legitimate user behavior and effectively bypass standard anomaly detection protocols.
Why does it take so long? Because most organizations lack “Forensic Readiness.” They treat forensics as something that happens after a disaster, hiring consultants to come in and sweep up the broken glass. But in a cloud environment, if you have not configured your logging and retention policies beforehand, there is no glass to sweep up. The evidence evaporated when the serverless function spun down.
This necessitates a shift in mindset. We must move from a reactive stance to a proactive preparation for investigation. As outlined in Forensic Readiness: Preparation for Investigations,6 forensic readiness is about structuring your IT environment so that valid, admissible evidence is automatically captured and preserved. It involves asking difficult questions before a breach occurs:
- If a specific API key was compromised today, would we have the logs to prove what data was accessed?
- Do we have a chain of custody for our cloud logs?
- Can we correlate activity across our multi-cloud environment?
Without affirmative answers to these questions, a breach becomes a black hole. You know data was lost, but you cannot determine whose data it was or how much was taken. This uncertainty is what drives regulatory fines and class-action lawsuits.
De-Risking the Dark Data
If we accept that total visibility is difficult to achieve in a complex cloud environment, we need a second line of defense. We need to ensure that even if data falls into the shadows, it remains toxic to the attacker.
This brings us to the concept of “Dark Data.” This is information that organizations collect, process, and store during regular business activities but generally fail to use for other purposes. It is the digital debris of the modern enterprise. Recent peer-reviewed work corroborates industry reports that a majority of organizational data is unexamined or “dark,” while a small fraction is business-critical. For example, a 2022 academic survey of EMEA firms, Demystifying Dark Data Characteristics In Small And Medium Enterprises: A Malaysian Experience,7 found roughly 54% dark data, 32% ROT, and 14% business-vital.
The danger of Dark Data is that it often contains Personally Identifiable Information (PII) that you are not even aware of. A developer might dump a production database to a test environment to run a quick query, intending to delete it later. They get distracted, and that copy sits there for three years. It is “Dark Data” to you, but it is a goldmine to a hacker.
The solution is a rigorous application of data protection techniques, specifically determining when data should be anonymized versus when it should be pseudonymized.
Many leaders conflate these two terms, but the distinction is vital for risk management. To understand the technical and legal differences, you should consult Anonymization vs. Pseudonymization Techniques: A Comprehensive Guide for Modern Data Protection.8
In the context of shadow risk, pseudonymization (replacing identifiers with reversible tokens) allows for business utility but still carries risk if the encryption keys are compromised. Anonymization (irreversibly stripping data of identifying characteristics) destroys the value to an attacker.
If that developer’s test database had been properly anonymized before being moved to a lower-security environment, the “shadow risk” would be neutralized. Even if an attacker found the neglected bucket, the data would be statistically useless.
The Strategic Blueprint: From Shadow to Light
Recognizing the problem is the first step. Solving it requires a coordinated effort between business leadership, legal teams, and IT operations. We cannot simply “buy” a solution to shadow data; we must architect it out of our systems.
Here is a practical, four-step blueprint for upgrading your forensic readiness and reducing shadow risk.
1. The Discovery Audit
You cannot protect what you cannot see. The first action item is to conduct a ruthless discovery audit of your cloud assets. This goes beyond looking at your billing dashboard.
- Scan for orphan resources: Use automated tools to identify storage buckets, unattached compute volumes, and load balancers that have not seen traffic in 90 days.
- Tagging enforcement: Implement a “No Tag, No Run” policy. Any cloud resource spun up without an owner tag, a project code, and a data classification tag should be automatically terminated by a script within 24 hours.
- Classify Dark Data: Utilize data discovery tools to scan unstructured data stores (like S3 buckets or file shares) for regex patterns matching credit card numbers, social security numbers, or patient IDs.
2. Centralized Immutable Logging
To achieve the forensic readiness discussed earlier, you must decouple your logging from your application.
- Ship logs immediately: Do not store logs on the same server or container that generates them. If that asset is compromised, the logs will be wiped. Stream logs in real-time to a centralized, write-once-read-many (WORM) storage bucket.
- Standardize formats: A major hurdle in investigations is parsing different log formats. Enforce a JSON schema for all application logs so that your security information and event management (SIEM) system can ingest them without manual parsing.

3. The “Privacy by Default” Pipeline
We need to stop treating data protection as a post-production step. It must be part of the Continuous Integration/Continuous Deployment (CI/CD) pipeline.
- Synthetic Data for Dev/Test: There is almost never a valid reason for production data to exist in a development environment. Invest in tools that generate synthetic data, fake data that maintains the statistical properties of real data, for testing purposes.
- Automated Anonymization: If real data must be moved (e.g., for analytics), it should pass through an automated “sanitization” gateway that applies the techniques detailed in our Anonymization vs. Pseudonymization guide before it lands in the destination bucket.
4. The Human Element
Shadow IT often stems from friction. Employees bypass security policies because the policies make their jobs harder.
- Streamline approval: If it takes two weeks to get a secure database provisioned, a developer will spin up an insecure one in two minutes on a personal credit card. Make the secure path the path of least resistance.
- Forensic drills: Just as you run fire drills, run “data hunting” drills. Challenge your security team to locate a specific piece of dummy data hidden in your cloud environment. Measure how long it takes them to find it.
Conclusion
The cloud has given us extraordinary capabilities. We can scale instantly, deploy globally, and innovate rapidly. But this speed has come with a hidden accumulation of risk. Shadow data, the silent byproduct of our digital velocity, is growing.
Ignoring this reality is not a strategy; it is a gamble. As the statistics clearly show, the cost of losing that gamble is rising every year. The longer an attacker can dwell in your systems unnoticed, the more catastrophic the damage will be.
However, this is not a hopeless situation. By acknowledging the existence of shadow data and committing to a strategy of forensic readiness, you can regain control. By understanding the nuances of serverless security, you can close the blind spots in your infrastructure. And by rigorously applying anonymization techniques, you can ensure that even if your perimeter is breached, your most valuable asset, your customer’s privacy, remains intact.
Emutare transforms your cloud strategy from reactive to proactively forensic-ready. We specialize in illuminating blind spots through rigorous discovery audits, resilient serverless architectures, and automated “Privacy by Default” pipelines. From neutralizing dark data risks with advanced anonymization to eliminating attacker dwell time, we ensure your organization is prepared before a breach occurs.
Stop flying blind. Partner with Emutare to execute your forensic upgrade and turn your unknown liabilities into secured assets today
References
- Verizon. (2025). 2025 Data Breach Investigations Report. https://www.verizon.com/business/resources/Tbb1/reports/2025-dbir-data-breach-investigations-report.pdf ↩︎
- Verizon. (2024). 2024 Data Breach Investigations Report. https://www.verizon.com/business/resources/reports/2024-dbir-data-breach-investigations-report.pdf ↩︎
- Emutare. (2025). Serverless Security: Functions as a Service (FaaS). https://insights.emutare.com/serverless-security-functions-as-a-service-faas/ ↩︎
- Hadil B. A, Manel A, Taher G. (2025). A comprehensive multi-vocal empirical study of ML cloud service misuses. arXiv. https://arxiv.org/pdf/2503.09815 ↩︎
- Ahmed, Z., Filani, A., Osifowokan, A. S., & Hutchful, N. (2025). The impact of data breaches in U.S. healthcare: A cost-benefit analysis of prevention vs. recovery. World Journal of Advanced Research and Reviews, 27(3), 1542–1549. https://doi.org/10.30574/wjarr.2025.27.3.3274 ↩︎
- Emutare. (2025). Forensic Readiness: Preparation for Investigations. https://insights.emutare.com/forensic-readiness-preparation-for-investigations/ ↩︎
- Ajis, A. F. M., Zakaria, S., & Ahmad, A. R. (2022). Demystifying dark data characteristics in small and medium enterprises: A Malaysian experience. Journal of Theoretical and Applied Information Technology, 100(5), 1525–1535. https://www.jatit.org/volumes/Vol100No5/27Vol100No5.pdf? ↩︎
- Emutare. (2025). Anonymization vs. Pseudonymization Techniques: A Comprehensive Guide for Modern Data Protection. https://insights.emutare.com/anonymization-vs-pseudonymization-techniques-a-comprehensive-guide-for-modern-data-protection/ ↩︎
Related Blog Posts
- Security Awareness Program Design: Beyond Compliance
- Vulnerability Management for Third-Party Applications: A Critical Security Imperative
- Securing API Gateways in Cloud-Native Architectures
- Data Subject Access Requests: Handling Process – A Comprehensive Guide for Australian Organizations
- Gamification in Security Awareness Training: Revolutionizing Cybersecurity Education Through Strategic Engagement
- Cross-Border Data Transfer: Legal Requirements
- Privacy by Design: Implementation Framework for Modern Organizations